最近刷算法题发现能想到用什么数据结构来高效率解题,太弱了具体实现和用法却不会。以前上学没好好听课,现在来恶补一下数据结构。
按照视点的不同,数据结构分为逻辑结构 和物理结构 。
逻辑结构:指数据元素之间的逻辑关系,这里的逻辑关系是指数据元素之间的前后关系,与数据在计算机中的存储位置无关。
物理结构:指数据的逻辑结构在计算机中的存储形式,也叫做存储结构。
数据的逻辑结构主要分为线性结构 和非线性结构 。
线性结构:数据元素之间是一对一线性关系,所有结点都最多只有一个直接前趋结点和一个直接后继结点。常见的有数组、队列、链表、栈 。
非线性结构:数据元素之间具有多个对应关系,一个结点可能有多个直接前趋结点和多个直接后继结点。常见的有多维数组、广义表、树结构和图结构等。
数据的物理结构(存储结构) ,表示数据元素之间的逻辑关系的存储形式,数据的逻辑结构根据需要可以采用多种存储结构,常用的存储结构有:
顺序存储:存储顺序是连续的,在内存中用一组地址连续的存储单元依次存储线性表的各个数据元素,其数据间的逻辑关系和物理关系是一致的。
链式存储:把数据元素存放在任意的存储单元里,这组存储单元不一定是连续的,元素节点存放数据元素和通过指针指向相邻元素的地址信息。
索引存储:除建立存储结点信息外,还建立附加的索引表来标识节点的地址。索引表由若干索引项组成。
散列存储:也称Hash存储,由节点的关键码值决定节点的存储地址。
常用的数据结构有:
数组(Array)
链表(Linked List)
栈(Stack)
队列(Queue)
串(String)
树(Tree)
集合和字典(Set & Map)
图(Graph)
数组(Array) 数组是最基本最常用的数据结构,是一种线性表顺序存储结构,用一段地址连续的内存空间来存储相同类型的数据元素,可通过数组名和下标进行数据的访问和更新。
优点:
无须为表示数组元素之间的逻辑关系而增加额外的存储空间
可以快速地存取表中任一位置的元素
缺点:
插入和删除操作需要移动大量元素
当数组长度变化较大时,难以确定存储空间的容量
造成存储空间的“碎片”
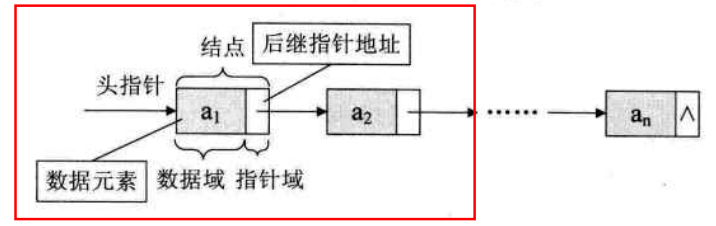
链表(Linked List) 单链表 用一组任意的存储单元存储线性表的数据元素,是一种物理存储单元上非连续的存储结构。
在链式结构中,除了存储数据元素信息(数据域 ),还要存储它的后继元素的地址(指针域 ),这两部分信息组成结点 。链表的每个结点只包含一个指针域称为单链表,对指针域进行反向链接,还可以形成双向链表或者循环链表。
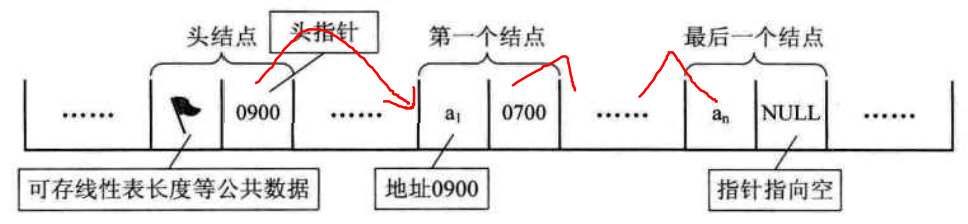
为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一结点,称为头结点 。头结点的数据域可以不储存任何信息,也可以储存链表的长度等公共数据。若链表为空表,则头结点的指针域为空(NULL)。
链表和数组在实际的使用过程中需要根据自身的优劣势进行选择,区别对比如下:
数组
链表
内存地址
连续的内存空间
任意的内存空间
访问方式
随机访问
顺序访问
线性表长度
长度固定,一般不可动态扩展
长度可动态变化
增删效率
低,需要移动被修改元素后的所有元素
高,只需修改指针指向
查询效率
高,可通过数组名和下标直接访问O(1)
低,只能通过遍历节点一次查询O(n)
单链表及常用操作C++实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 #include <iostream> using namespace std;class Node { public : int data; Node *next; }; class LinkList { public : LinkList (); ~LinkList (); void CreateLinkList (int n) void TravalLinkList () int GetLength () bool IsEmpty () Node *Find (int data) ; void InsertElemAtEnd (int data) void InsertElemAtIndex (int data,int n) void InsertElemAtHead (int data) void DeleteElemAtEnd () void DeleteAll () void DeleteElemAtPoint (int data) void DeleteElemAtHead () private : Node *head; }; LinkList::LinkList (){ head = new Node; head->data = 0 ; head->next = nullptr ; } LinkList::~LinkList (){ Node *ptem = nullptr ; while (head->next){ ptem = head; head = head->next; delete ptem; } delete head; head = nullptr ; } void LinkList::CreateLinkList (int n) if (n<=0 ) cout<<"n error" <<endl; else { Node *pnew,*ptem; ptem = head; for (int i=0 ;i<n;i++){ pnew = new Node; cout << "input " << i + 1 << " value " ; cin>>pnew->data; pnew->next = nullptr ; ptem->next = pnew; ptem = pnew; } } } void LinkList::TravalLinkList () if (head->next==nullptr ) cout<<"Empty LinkList" <<endl; else { Node *p = head; while (p->next!=nullptr ){ p = p->next; cout<<p->data<<" " ; } } } int LinkList::GetLength () Node *p = head; int count = 0 ; while (p->next){ count++; p = p->next; } return count; } bool LinkList::IsEmpty () if (head->next) return false ; return true ; } Node *LinkList::Find (int data) { Node *p = head; while (p->next){ if (p->data==data) return p; p = p->next; } return nullptr ; } void LinkList::InsertElemAtEnd (int data) Node *p = head; Node *pnew = new Node; pnew->data = data; pnew->next = nullptr ; while (p->next){ p = p->next; } p->next = pnew; } void LinkList::InsertElemAtIndex (int data,int n) if (n<1 || n>GetLength ()) cout<<"n error" <<endl; else { Node *p = head; Node *pnew = new Node; pnew->data = data; int i = 1 ; while (i<n){ p = p->next; i++; } pnew->next = p->next; p->next = pnew; } } void LinkList::InsertElemAtHead (int data) Node *pnew = new Node; pnew->data = data; pnew->next = head->next; head->next = pnew; } void LinkList::DeleteElemAtEnd () Node *p = head; Node *ptem = nullptr ; while (p->next){ ptem = p; p = p->next; } delete p; p = nullptr ; ptem->next = nullptr ; } void LinkList::DeleteAll () Node *p = head->next; Node *ptem = new Node; while (p){ ptem = p; p = p->next; head->next = p; delete ptem; } head->next = nullptr ; } void LinkList::DeleteElemAtPoint (int data) Node *ptem = new Node; Node *p = head; while (p->data!=data){ ptem = p; p = p->next; } ptem->next = p->next; delete p; p = nullptr ; } void LinkList::DeleteElemAtHead () Node *p = head->next; head->next = p->next; delete p; p = nullptr ; }
循环链表 将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circuar linkedlist)。循环链表解决了一个很麻烦的问题即如何从当中一个结点出发,访问到链表的全部结点。
为了方便查找开始结点和终端结点,不再使用头指针,而是用指向终端结点的尾指针 来表示循环链表。
约瑟夫环问题 :已知n个人(以编号0,1,2,3,…,n)分别表示)围坐在一张圆桌周围。从编号0的人开始报数,数到m的那个人出列;他的下一个人又从1开始报数,数到m的那个人又出列:依此规律重复下去,知道圆桌周围的人全都出列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 # include <iostream> using namespace std;struct Node { int data; Node *next; }; class CircleList {private : Node *head; public : CircleList (); ~CircleList (); void CreateCircleList (int n) void InsertCircleList (int pos,int data) void DeleteCircleList () void DeleteNode (int pos) void TravalCircleList () int GetLength () Node *GetHead () ; }; CircleList::CircleList (){ head = new Node; head->data = 0 ; head->next = head; } CircleList::~CircleList (){ Node *ptem = head->next; while (ptem!=head){ head->next = ptem->next; delete ptem; ptem = head->next; } delete head; head = nullptr ; } void CircleList::CreateCircleList (int n) if (n<=0 ){ cout<<"n error" <<endl; }else { Node *pnew, *ptem = head; for (int i=0 ;i<n;i++){ pnew = new Node; cout << "input " << i + 1 << " value " ; cin>>pnew->data; pnew->next= head; ptem->next = pnew; ptem = pnew; } } } int CircleList::GetLength () int len = 0 ; Node *p = head->next; while (p!=head){ len++; p = p->next; } return len; } void CircleList::InsertCircleList (int pos,int data) if (pos>GetLength ()||pos<1 ){ cout<<"pos error" <<endl; }else { Node *pnew = new Node; Node *p = head; while ((pos--)>1 ){ p = p->next; } pnew->data = data; pnew->next = p->next; p->next = pnew; } } void CircleList::DeleteNode (int pos) Node *p = head,*pd; if (pos==0 ){ while (p->next!=head){ p = p->next; } head = head->next; }else if (pos>0 ){ while (pos-->1 ){ p = p->next; } } pd = p->next; p->next = pd->next; delete pd; pd = nullptr ; } void CircleList::DeleteCircleList () Node *ptem = head->next; while (ptem!=head) { head->next = ptem->next; delete ptem; ptem = head->next; } } void CircleList::TravalCircleList () Node *ptem = head->next; if (ptem==head){ cout<<"empty" <<endl; }else { while (ptem!=head){ cout<<ptem->data<<" " ; ptem = ptem->next; } } } Node *CircleList::GetHead () { return head; } int main () int m,n; cout<<"n m" <<endl; cin>>n>>m; CircleList clist; clist.CreateCircleList (n-1 ); Node *p = clist.GetHead (),*pre; for (int i=1 ;i<n;i++){ for (int j=1 ;j<m;j++){ pre = p; p = p->next; } cout<<"delete: " <<p->data<<endl; pre->next = p->next; delete p; p = pre->next; } }
用数学方式解决属实没看懂,参考 :在 n 个数中最后留下来的数 = 在 n 中去除第 m 个数后剩下 n-1 个数中留下来的数。在0-n-1个数:0,1,2,m-2,m-1,m,…,n-1,去除一个m-1后,剩下为:0,1,2,m-2,m,…,n-1,在这 n-1 个数中,每次计数需要从 m 开始,推导公式 f(n,m)=(f(n−1,m)+m)%n
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public : int lastRemaining (int n, int m) if (n == 0 || m == 0 ) return -1 ; int s = 0 ; for (int i = 2 ; i <= n; i++) { s = (s + m) % i; } return s; } };
双向链表 双向链表(double linkedlist)是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。
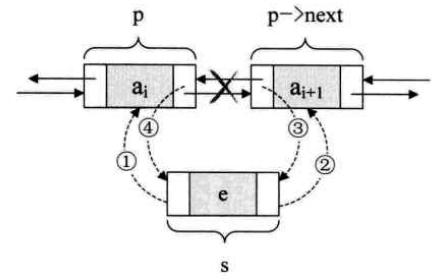
在插入和删除时,需要修改两个指针变量。假设存储元素 e 的结点为 s,要实现将结点 s 插入到结点 p 和 p->next 之间需要下面几步。先搞定 s 的前驱和后继,再搞定后结点的前驱,最后解决前结点的后继。
1 2 3 4 s->prior = p; s->next = p->next; p->next->prior = s; p->next = s;
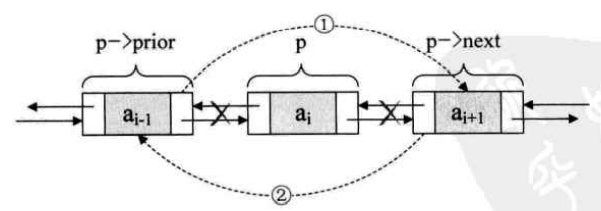
若要删除结点 p,只需要下面两个步骤
1 2 3 p->prior->next = p->next; p->next->prior = p->prior; delete
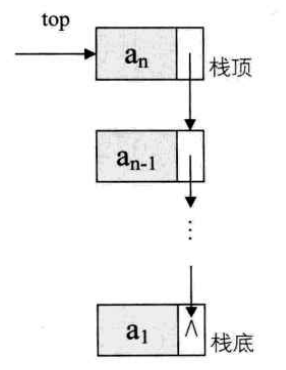
栈(Stack) 栈(Stack) 是限定仅在表尾进行插入和删除操作的线性表。
允许插入和删除的一端称为栈顶(top),另一端称为 栈底(bottom),不含任何数据元素的栈称为 空栈 。栈又称为**后进先出(LIFO)**的线性表,简称 LIFO 结构。
栈是线性表的特例,也有两种典型的存储方式:基于数组的顺序存储(顺序栈 )和基于链表的链式存储(链式栈 )
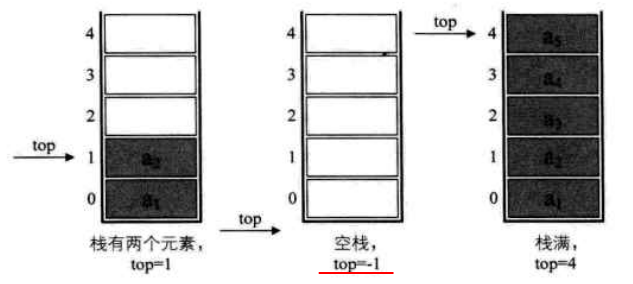
顺序栈 用数组下标为 0 的一端作为栈底,数组最大允许存放元素个数为 maxSize,定义一个 top 变量来指示栈顶元素在数组中的位置,top = -1 时,置栈为空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 # include <iostream> using namespace std;class SeqStack {private : int *data; int top; int maxSize; public : SeqStack (int ms=10 ); ~SeqStack (); void Push (int x) void Pop () int GetTop () bool IsEmoty () void MakeEmpty () -1 ;}; int GetSize () return top+1 ;}; }; SeqStack::SeqStack (int ms){ maxSize = ms; data = new int [maxSize]; top = -1 ; } SeqStack::~SeqStack (){ delete []data; } void SeqStack::Push (int x) if (top == maxSize-1 ){ cout<<"stack overflow!" <<endl; }else { data[++top] = x; } } void SeqStack::Pop () if (top == -1 ){ cout<<"stack empty!" <<endl; }else { top--; } } int SeqStack::GetTop () if (top == -1 ){ cout<<"stack empty!" <<endl; exit (EXIT_FAILURE); }else { return data[top]; } } bool SeqStack::IsEmoty () return (top == -1 )? true :false ; }
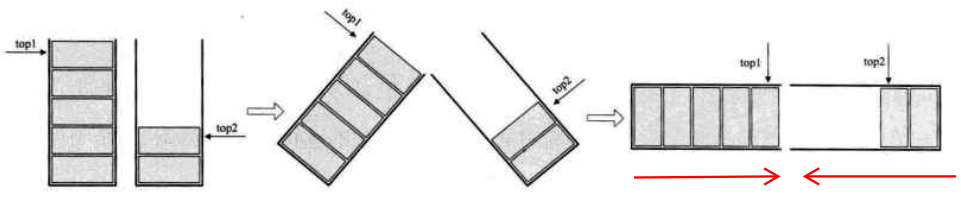
如果有两个相同类型的栈,我们为它们各自开辟了数组空间,极有可能是第一个栈已经满了,再进栈就溢出了,而另一个栈还有很多存储空间空闲。我们完全可以用一个数组来存储两个栈,数组有两个端点,两个栈有两个栈底,让一个栈的栈底为数组的始端,即下标为 0 处,另一个栈为栈的末端,即下标为数组长度 maxSize-1 处。这样两个栈如果增加元素,就是两端点向中间延伸。
当然,这只是针对两个具有相同数据类型的栈的一个设计上的技巧,如果不是相同数据类型的栈,或者是多个栈共享栈空间,这种办法不但不能更好地处理问题,反而会使问题变得更复杂。
链式栈 栈的链式存储结构,简称为链式栈。链式栈的栈顶在链表的表头,栈的插入和删除操作都在表头(不需要头结点)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 # include <iostream> using namespace std;struct Node { int data; Node *next; }; class LinkStack { private : Node *top; public : LinkStack (){top = nullptr ;}; ~LinkStack (); void Push (int x) void Pop () int GetTop () int GetSize () void MakeEmpty () }; LinkStack::~LinkStack (){ Node *p; while (top != nullptr ){ p = top; top = top->next; delete p; } } void LinkStack::Push (int x) Node *pnew = new Node; pnew->data = x; pnew->next = top; top = pnew; } void LinkStack::Pop () if (top != nullptr ){ Node *pd = top; top = top->next; delete pd; }else cout<<"stack empty" <<endl; } int LinkStack::GetTop () if (top != nullptr ){ return top->data; }else { cout<<"stack empty" <<endl; exit (EXIT_FAILURE); } } int LinkStack::GetSize () Node *p = top; int count = 0 ; while (p != nullptr ){ count++; p = p->next; } return count; } void LinkStack::MakeEmpty () Node *p; while (top != nullptr ){ p = top; top = top->next; delete p; } }
栈的应用 现在许多高级语言,都对栈结构进行了封装,可以不用关注它的实现细节,可以直接使用 stack 的 push 和 pop 等方法。
把一个直接或间接调用自己的函数,称为递归函数 。每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。
利用后缀表达 法书写表达式不需要括号,也称为逆波兰表示(RPN)。后缀表达式的计算:从左到右遍历表达式的每个数字和操作符,遇到是数字就进栈,遇到是操作符 op,就将栈顶连续两个数字 X(先) 和 Y(后) 出栈,进行运算 Y op X,计算结果进栈,直到表达式所有项都遍历处理完,栈顶存放的就是表达式最终的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # include <iostream> # include <stack> # include <string> using namespace std;int main () string exp; stack<int > st; cin>>exp; for (int i=0 ;i<exp.length ();i++){ if (exp[i]>='0' && exp[i]<='9' ) st.push (exp[i]-'0' ); else { int x = st.top (); st.pop (); int y = st.top (); st.pop (); switch case '+' : st.push (y+x);break ; case '-' : st.push (y-x);break ; case '*' : st.push (y*x);break ; case '/' : st.push (y/x);break ; default : break ; } } cout<<st.top ()<<endl; } }
上述代码看着正确,运行也正确,可是有个很大的缺陷,只能计算 10 以内的加减乘除表达式。
编译程序利用后缀表达法仅用一个栈就可以很快算出表达式的值,而我们平时用的都是标准的四则运算表达式(中缀表达式),如何将中缀表达转换为后缀表达 ?
手工方式
栈的方式
规则:从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;若是符号,则判断其与栈顶符号的优先级,是右括号或优先级不高于栈顶符号(乘除优先加减),则栈顶元素依次出栈并输出操作符元素,并将当前符号进栈,一直到最终输出后缀表达式为止。
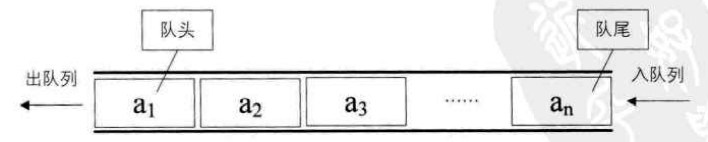
队列(Queue) 队列是只允许在表的一端插入,另一端删除的线性表。是一种先进先出(FIFO)结构的线性表,运行插入的一端为队尾,允许删除的一端为队头。
循环队列 循环队列是基于数组的存储方式,把数组的前端和后端连接起来,形成一个环形的表,用 front 和 rear 分别指示队列的队头和队尾元素下一位置,初始化时都置为 0,maxSize 是数组的最大长度。在队尾插入新元素和队头删除元素时,队尾和队头指针分别按顺时针方向进 1,两指针进到 maxSize -1 后,再进一个位置就自动到 0。
队头指针进 1:front = (front+1)%maxSize
队尾指针进 1:rear = (rear+1)%maxSize
如果循环列表读取元素速度快于存储速度,队头很快追上队尾,当 front == rear 时,队列就变成空队列;如果列表存储元素速度快于读取速度,队尾很快追上队头,当 (rear+1)%maxSize == front 时,队列已满。在循环列表中,最多存放 maxSize-1 个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 # include <iostream> using namespace std;class SeqQueue { private : int rear,front; int *data; int maxSize; public : SeqQueue (int ms = 10 ); ~SeqQueue (); bool IsFull () return ((rear+1 )%maxSize==front)?true :false ;} void EnQueue (int x) void DeQueue () int GetFront () int GetSize () return (rear-front+maxSize)%maxSize;} }; SeqQueue::SeqQueue (int ms){ maxSize = ms; rear = front = 0 ; data = new int [maxSize]; } SeqQueue::~SeqQueue (){ delete []data; } void SeqQueue::EnQueue (int x) if (IsFull ()==true ){ cout<<"Queue is full" <<endl; }else { data[rear] = x; rear = (rear+1 )%maxSize; } } void SeqQueue::DeQueue () if (rear == front){ cout<<"Queue is empty" <<endl; }else { front = (front+1 )%maxSize; } } int SeqQueue::GetFront () if (rear == front){ cout<<"Queue is empty" <<endl; exit (EXIT_FAILURE); }else { return data[front]; } }
链式队列 链式队列是基于单链表的存储方式,队列的队头指针指向单链表的第一个结点,队尾指针指向单链表的最后一个结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 # include <iostream> using namespace std;struct Node { int data; Node *next; }; class LinkQueue {private : Node *front,*rear; public : LinkQueue (); ~LinkQueue (); bool Isempty () return (front==nullptr )? true :false ;} void EnQueue (int x) void DeQueue () int GetFront () int GetSize () void MakeEmpty () }; LinkQueue::LinkQueue (){ front = rear = nullptr ; } LinkQueue::~LinkQueue (){ MakeEmpty (); } void LinkQueue::EnQueue (int x) if (front == nullptr ){ front = rear = new Node; rear->data = x; rear->next = nullptr ; }else { Node *pn = new Node; pn->data = x; pn->next = nullptr ; rear->next = pn; rear = pn; } } void LinkQueue::DeQueue () if (Isempty ()){ cout<<"Queue is empty" <<endl; exit (EXIT_FAILURE); }else { Node *p = front; front = front->next; delete p; } } int LinkQueue::GetFront () if (Isempty ()){ cout<<"Queue is empty" <<endl; exit (EXIT_FAILURE); }else { return front->data; } } int LinkQueue::GetSize () Node *p = front; int count = 0 ; while (p!=nullptr ){ p = p->next; count++; } return count; } void LinkQueue::MakeEmpty () Node *pd; while (front!=nullptr ){ pd = front; front = front->next; delete pd; } }
队列应用 二项展开式 (a+b)^i 的系数,其系数构成杨辉三角。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # include <iostream> # include <queue> using namespace std;int main () int n; int i,j,t,s=0 ; cin>>n; queue<int > q; q.push (1 ); q.push (1 ); for (i=1 ;i<=n;i++){ q.push (0 ); for (j=1 ;j<=(i+2 );j++){ t = q.front (); q.pop (); q.push (s+t); s = t; if (s) cout<<s<<" " ; } cout<<endl; } return 0 ; }
串(String) 见 https://gzwangu.github.io/2021/10/21/C-%E4%B8%ADstring%E7%9A%84%E7%94%A8%E6%B3%95/
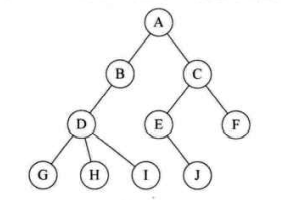
树(Tree) 树是由 n(n>=0)个有限结点组成一个具有层次关系的集合。n=0 时为空树,非空树具有以下的特点:
每个结点有零个或多个子结点;
没有父结点的节点称为根(Root)结点,根结点是唯一的;
每一个非根结点有且只有一个父结点;
除了根结点外,每个子结点可以分为多个不相交的子树;
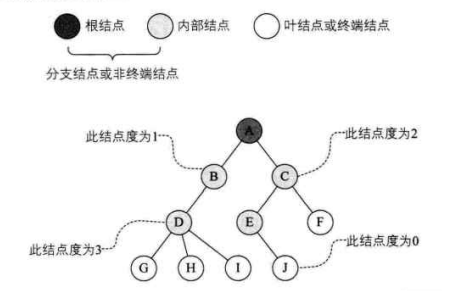
相关概念 树的结点包含一个数据元素及若干指向其子树的分支。结点拥有的子树数称为结点的度 (Degree)。度为 0 的结点称为叶结点(Leaf)或终端结点;度不为 0 的结点称为非终端结点或分支结点。除根结点之外,分支结点也称为内部结点。树的度是树内各结点的度的最大值。如图所示,因为这棵树结点的度的最大值是结点 D 的度为 3,所以树的度也为 3。
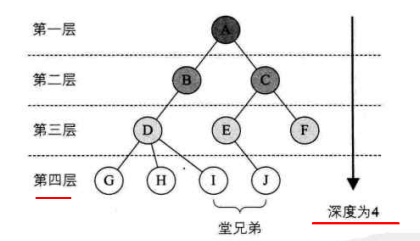
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)。同一个双亲的孩子之间互称兄弟(Sibling)。
结点的层次从根开始定义起,根为第一层,根的孩子为第二层。若某结点在第 i 层,则其子树的根就在第 i+1 层,其双亲在同一层的结点互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度 ,当前树的深度为4。
森林(Forest)是 m(m>=0)棵互不相交的树的集合。
在日常的应用中,我们讨论和用的更多的是树的其中一种结构,就是二叉树 。
二叉树 二叉树(Binary Tree)是 n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。二叉树的特点有:
每个结点最多有两棵子树,不存在度大于 2 的结点
左子树和右子树是有顺序的,次序不能任意颠倒
即使树中某结点只有一棵子树,也要区分它是左子树还是右子树
满二叉树 :在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
完全二叉树 :对一棵具有 n 个结点的二叉树按层序编号,如果编号为i(1<i<n)的结点与同样深度的满二叉树中编号为 i 的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
二叉树的性质
在二叉树的第 i 层上至多有2^(i-1)个结点(i≥1)
深度为 k 的二叉树至多有2^(k-1)个结点(k>1)
对任何一棵二叉树 T,如果其叶子结点数为 n0,度为 2 的结点数为 n2,则 n0 = n2 + 1。
具有 n 个结点的完全二叉树的深度为[(log2)n]+1([x]表示不大于 x 的最大整数)
二叉链表 二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域是比较合适的,我们称这样的链表叫做二叉链表。
lchild | data | rchid ,其中 data 是数据域,lchild 和 rchid 都是指针域,分别存放指向左孩子和右孩子的指针。
二叉树有深度遍历和层次遍历,深度遍历有前序、中序以及后序三种遍历方法。
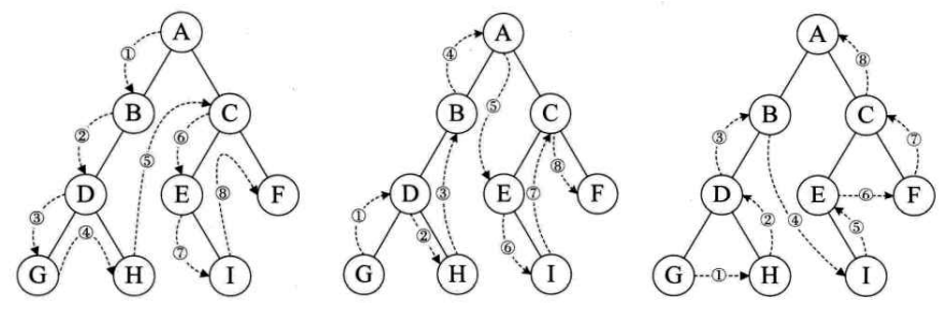
前序遍历:根结点 —> 左子树 —> 右子树
中序遍历:左子树 —> 根结点 —> 右子树
后序遍历:左子树 —> 右子树 —> 根结点
层次遍历:从上而下逐层,同一层中从左到右遍历
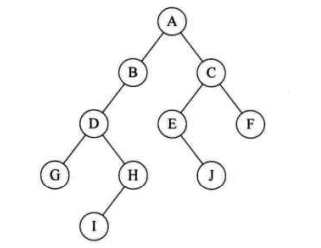
前序遍历:ABDGHCEIF;中序遍历:GDHBAEICF;后序遍历:GHDBIEFCA;层次遍历:ABCDEFGHI
已知先序和后序,不能唯一确定二叉树
已知先序或后序,而又知中序,则能唯一确定二叉树
先序、中序相同时,二叉树没有左子树
后序、中序相同时,二叉树没有右子树
后序、先序相同时,只有一个根节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 #include <iostream> #include <vector> #include <queue> #include <stack> using namespace std;struct BtNode { int data; BtNode *left; BtNode *right; }; class BinaryTree { private : BtNode *root; public : BinaryTree (){root = nullptr ;} ~BinaryTree (); BtNode* getRoot () {return root;} void insert (int data) void inorder (BtNode *root) void preorder (BtNode *root) void postorder (BtNode *root) void levelorder (BtNode *root) void preorder_nonrecursive (BtNode *root) void postorder_nonrecursive (BtNode *root) void inorder_nonrecursive (BtNode *root) void deleteNode (int data) void deleteTree (BtNode *root) int getHeight (BtNode *root) int countLeaf (BtNode *root) int countNode (BtNode *root) BtNode* search (BtNode *root, int data) ; BtNode* minValue (BtNode *root) ; BtNode* maxValue (BtNode *root) ; BtNode* successor (BtNode *root, int data) ; BtNode* predecessor (BtNode *root, int data) ; }; BinaryTree::~BinaryTree (){ deleteTree (root); } void BinaryTree::insert (int data) BtNode *newNode = new BtNode (); newNode->data = data; newNode->left = nullptr ; newNode->right = nullptr ; if (root == nullptr ){ root = newNode; } else { BtNode *temp = root; while (temp != nullptr ){ if (data < temp->data){ if (temp->left == nullptr ){ temp->left = newNode; break ; } else { temp = temp->left; } } else { if (temp->right == nullptr ){ temp->right = newNode; break ; } else { temp = temp->right; } } } } } void BinaryTree::inorder (BtNode *root) if (root != nullptr ){ inorder (root->left); cout<<root->data<<" " ; inorder (root->right); } } void BinaryTree::preorder (BtNode *root) if (root != nullptr ){ cout<<root->data<<" " ; preorder (root->left); preorder (root->right); } } void BinaryTree::postorder (BtNode *root) if (root != nullptr ){ postorder (root->left); postorder (root->right); cout<<root->data<<" " ; } } void BinaryTree::levelorder (BtNode *root) if (root == nullptr ){ return ; } BtNode *temp = root; queue<BtNode*> q; q.push (temp); while (!q.empty ()){ temp = q.front (); q.pop (); cout<<temp->data<<" " ; if (temp->left != nullptr ){ q.push (temp->left); } if (temp->right != nullptr ){ q.push (temp->right); } } } void BinaryTree::deleteNode (int data) BtNode *temp = root; BtNode *parent = nullptr ; while (temp != nullptr ){ if (temp->data == data){ break ; } else { parent = temp; if (data < temp->data){ temp = temp->left; } else { temp = temp->right; } } } if (temp == nullptr ){ cout<<"没有找到要删除的节点" <<endl; return ; } if (temp->left == nullptr && temp->right == nullptr ){ if (parent == nullptr ){ root = nullptr ; } else { if (parent->left == temp){ parent->left = nullptr ; } else { parent->right = nullptr ; } } } else if (temp->left == nullptr ){ if (parent == nullptr ){ root = temp->right; } else { if (parent->left == temp){ parent->left = temp->right; } else { parent->right = temp->right; } } } else if (temp->right == nullptr ){ if (parent == nullptr ){ root = temp->left; } else { if (parent->left == temp){ parent->left = temp->left; } else { parent->right = temp->left; } } } else { BtNode *successor = minValue (temp->right); temp->data = successor->data; deleteNode (successor->data); } } void BinaryTree::deleteTree (BtNode *root) if (root != nullptr ){ deleteTree (root->left); deleteTree (root->right); delete root; } } int BinaryTree::getHeight (BtNode *root) if (root == nullptr ){ return 0 ; } int leftHeight = getHeight (root->left); int rightHeight = getHeight (root->right); return leftHeight > rightHeight ? leftHeight + 1 : rightHeight + 1 ; } int BinaryTree::countLeaf (BtNode *root) if (root == nullptr ){ return 0 ; } if (root->left == nullptr && root->right == nullptr ){ return 1 ; } else { return countLeaf (root->left) + countLeaf (root->right); } } int BinaryTree::countNode (BtNode *root) if (root == nullptr ){ return 0 ; } return countNode (root->left) + countNode (root->right) + 1 ; } BtNode* BinaryTree::search (BtNode *root, int data) { if (root == nullptr ){ return nullptr ; } if (root->data == data){ return root; } else { if (data < root->data){ return search (root->left, data); } else { return search (root->right, data); } } } BtNode* BinaryTree::minValue (BtNode *root) { BtNode *temp = root; while (temp->left != nullptr ){ temp = temp->left; } return temp; } BtNode* BinaryTree::maxValue (BtNode *root) { BtNode *temp = root; while (temp->right != nullptr ){ temp = temp->right; } return temp; } BtNode* BinaryTree::successor (BtNode *root, int data) { BtNode *temp = search (root, data); if (temp == nullptr ){ return nullptr ; } if (temp->right != nullptr ){ return minValue (temp->right); } BtNode *parent = root; while (parent != nullptr ){ if (parent->left == temp){ return parent; } else { parent = parent->left; } } return nullptr ; } BtNode* BinaryTree::predecessor (BtNode *root, int data) { BtNode *temp = search (root, data); if (temp == nullptr ){ return nullptr ; } if (temp->left != nullptr ){ return maxValue (temp->left); } BtNode *parent = root; while (parent != nullptr ){ if (parent->right == temp){ return parent; } else { parent = parent->right; } } return nullptr ; } void BinaryTree::preorder_nonrecursive (BtNode *root) stack<BtNode*> s; BtNode *p = root; while (p != nullptr || !s.empty ()){ while (p != nullptr ){ cout<<p->data<<" " ; s.push (p); p = p->left; } p = s.top (); s.pop (); p = p->right; } } void BinaryTree::inorder_nonrecursive (BtNode *root) stack<BtNode*> s; BtNode *p = root; while (p != nullptr || !s.empty ()){ while (p != nullptr ){ s.push (p); p = p->left; } p = s.top (); s.pop (); cout<<p->data<<" " ; p = p->right; } } void BinaryTree::postorder_nonrecursive (BtNode *root) stack<BtNode*> s; BtNode *p = root; BtNode *pre = nullptr ; while (p != nullptr || !s.empty ()){ while (p != nullptr ){ s.push (p); p = p->left; } p = s.top (); if (p->right == nullptr || p->right == pre){ cout<<p->data<<" " ; pre = p; s.pop (); p = nullptr ; }else { p = p->right; } } } int main () BinaryTree btree; vector<int > btarry = { 7 , 4 , 2 , 3 , 15 , 35 , 6 , 45 }; for (int bta: btarry){ btree.insert (bta); } cout<<"前序遍历:" <<endl; btree.preorder (btree.getRoot ()); cout<<endl; btree.preorder_nonrecursive (btree.getRoot ()); cout<<endl; cout<<"中序遍历:" <<endl; btree.inorder (btree.getRoot ()); cout<<endl; btree.inorder_nonrecursive (btree.getRoot ()); cout<<endl; cout<<"后序遍历:" <<endl; btree.postorder (btree.getRoot ()); cout<<endl; btree.postorder_nonrecursive (btree.getRoot ()); cout<<endl; cout<<"层次遍历:" <<endl; btree.levelorder (btree.getRoot ()); cout<<endl; btree.levelorder_nonrecursive (btree.getRoot ()); }
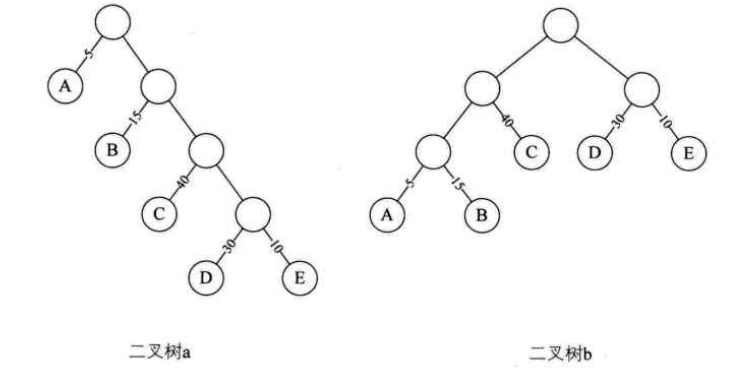
Huffman树及应用 从树中一个结点到另一个结点之间的分支构成两个结点之间的路径 ,路径上的分支数目称做路径长度 。如二叉树a中,根结点到结点D的路径长度就为4,二叉树b中根结点到结点D的路径长度为2。树的路径长度就是从树根到每一结点的路径长度之和。二叉树a的树路径长度就为1+1+2+2+3+3+4+4=20。二叉树b的树路径长度就为1+2+3+3+2+1+2+2=16。
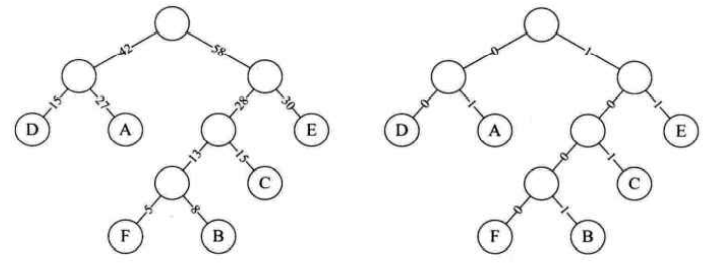
考虑到带权的结点,结点的带权的路径长度为从该结点到树根之间的路径长度与结点上权的乘积。树的带权路径长度为树中所有叶子结点的带权路径长度之和。其中带权路径长度WPL最小的二叉树称做哈夫曼树 ,也称为最优二叉树。
哈夫曼算法描述
根据给定的n个权值{ W1,W2…,Wn }构成n棵二叉树的集合F={T1,T2…,Tn},其中每棵二叉树Ti中只有一个带权为Wi根结点,其左右子树均为空。
在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
在F中删除这两棵树,同时将新得到的二叉树加入F中。
重复2和3步骤,直到F只含一棵树为止。这棵树便是赫夫曼树。
哈夫曼编码
假设六个字母的频率为A 27, B 8,C 15, D 15,E 30,F5,合起来正好是100%。那就意味着,我们完全可以重新按照赫夫曼树来规划它们。
字母
A
B
C
D
E
F
编码
01
1001
101
00
11
1000
集合和字典(Set & Map) 集合(Set) 集合是成员(元素)的一个集群,集合中的成员可以是原子(单元素),也可以是集合,集合的成员必须是互不相同的。可以采用位向量或有序链表实现集合。
set集合是c++ stl库中自带的一个容器,set具有以下两个特点:
set中的元素都是排好序的
set集合中没有重复的元素
set跟vector差不多,它跟vector的唯一区别就是,set里面的元素是有序的且唯一的,只要你往set里添加元素,它就会自动排序,而且,如果你添加的元素set里面本来就存在,那么这次添加操作就不执行。
set集合常用操作:
begin() 返回set容器的第一个元素的地址
end() 返回set容器的最后一个元素地址
clear() 删除set容器中的所有的元素
empty() 判断set容器是否为空
max_size() 返回set容器可能包含的元素最大个数
size() 返回当前set容器中的元素个数
erase(it) 删除迭代器指针it处元素
insert(a) 插入某个元素
当set集合中的元素为结构体时,该结构体必须实现运算符‘<’的重载
字典(Map) 讨论字典抽象数据结构类型时,从键(key)到值(value)的映射,把字典定义为<key-value>对的集合。
字典的组织方式有:
map是c++ stl库中自带的一个容器,它提供一对一的数据处理能力,是一种二叉树的数据存储结构。map内部自建一颗红黑树(一 种非严格意义上的平衡二叉树),这颗树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。map具有以下特点:
键与值一 一对应
键唯一,不存在相同的键对应不同的值。
按Key有序排列
根据key值快速查找记录,查找的复杂度基本是Log(N)
map集合常用操作:
begin 指向起始
end 指向末尾
rbegin 指向倒序起始(即末尾)
rend 指向倒序末尾(即起始)
empty 判断容器是否为空
size 返回容器大小
max_size 返回容器最大尺寸
元素访问 operater[ ] 和 at
insert 插入元素
erase 删除元素
swap 交换两个map容器内容
clear 清除容器
emplace 构造并插入元素
find 获得指向元素的迭代器
count 对某个键的元素计数
lower_bound 返回下边界的迭代器
upper_bound 返回上边界的迭代器
equal_range 获得相同元素的范围
图(Graph)